Methods of Offering Knowledge to a Mannequin
Many organizations at the moment are exploring the facility of generative AI to enhance their effectivity and acquire new capabilities. Typically, to completely unlock these powers, AI should have entry to the related enterprise knowledge. Giant Language Fashions (LLMs) are educated on publicly out there knowledge (e.g. Wikipedia articles, books, internet index, and so on.), which is sufficient for a lot of general-purpose purposes, however there are many others which might be extremely depending on non-public knowledge, particularly in enterprise environments.
There are three principal methods to supply new knowledge to a mannequin:
- Pre-training a mannequin from scratch. This not often is sensible for many firms as a result of it is rather costly and requires a variety of assets and technical experience.
- Advantageous-tuning an current general-purpose LLM. This may cut back the useful resource necessities in comparison with pre-training, however nonetheless requires vital assets and experience. Advantageous-tuning produces specialised fashions which have higher efficiency in a website for which it’s finetuned for however could have worse efficiency in others.
- Retrieval augmented era (RAG). The thought is to fetch knowledge related to a question and embody it within the LLM context in order that it might “floor” its personal outputs in that data. Such related knowledge on this context is known as “grounding knowledge”. RAG enhances generic LLM fashions, however the quantity of data that may be offered is proscribed by the LLM context window measurement (quantity of textual content the LLM can course of without delay, when the knowledge is generated).
At present, RAG is essentially the most accessible means to supply new data to an LLM, so let’s concentrate on this methodology and dive somewhat deeper.
Retrieval Augmented Technology
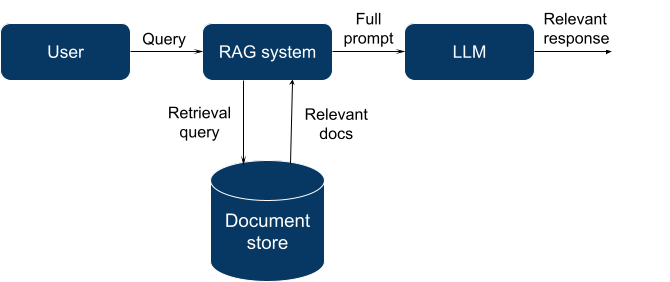
Basically, RAG means utilizing a search or retrieval engine to fetch a related set of paperwork for a specified question.
For this objective, we will use many current programs: a full-text search engine (like Elasticsearch + conventional data retrieval strategies), a general-purpose database with a vector search extension (Postgres with pgvector, Elasticsearch with vector search plugin), or a specialised database that was created particularly for vector search.
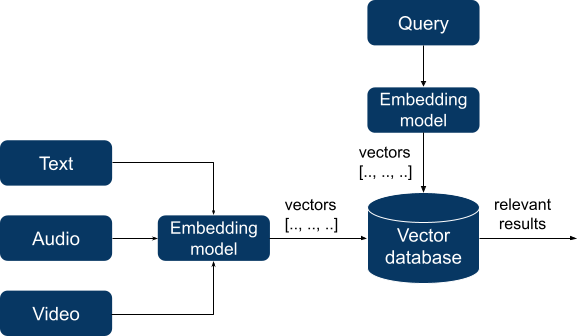
In two latter instances, RAG is much like semantic search. For a very long time, semantic search was a extremely specialised and sophisticated area with unique question languages and area of interest databases. Indexing knowledge required in depth preparation and constructing data graphs, however current progress in deep studying has dramatically modified the panorama. Trendy semantic search purposes now rely upon embedding fashions that efficiently study semantic patterns in offered knowledge. These fashions take unstructured knowledge (textual content, audio, and even video) as enter and remodel them into vectors of numbers of a set size, thus turning unstructured knowledge right into a numeric kind that may very well be used for calculations Then it turns into doable to calculate the gap between vectors utilizing a selected distance metric, and the ensuing distance will mirror the semantic similarity between vectors and, in flip, between items of unique knowledge.
These vectors are listed by a vector database and, when querying, our question can be remodeled right into a vector. The database searches for the N closest vectors (in keeping with a selected distance metric like cosine similarity) to a question vector and returns them.
A vector database is liable for these 3 issues:
- Indexing. The database builds an index of vectors utilizing some built-in algorithm (e.g. locality-sensitive hashing (LSH) or hierarchical navigable small world (HNSW)) to precompute knowledge to hurry up querying.
- Querying. The database makes use of a question vector and an index to search out essentially the most related vectors in a database.
- Submit-processing. After the outcome set is fashioned, typically we’d need to run a further step like metadata filtering or re-ranking throughout the outcome set to enhance the end result.
The aim of a vector database is to supply a quick, dependable, and environment friendly strategy to retailer and question knowledge. Retrieval pace and search high quality could be influenced by the collection of index kind. Along with the already talked about LSH and HNSW there are others, every with its personal set of strengths and weaknesses. Most databases make the selection for us, however in some, you possibly can select an index kind manually to regulate the tradeoff between pace and accuracy.
At DataRobot, we consider the approach is right here to remain. Advantageous-tuning can require very refined knowledge preparation to show uncooked textual content into training-ready knowledge, and it’s extra of an artwork than a science to coax LLMs into “studying” new info by fine-tuning whereas sustaining their normal data and instruction-following conduct.
LLMs are usually superb at making use of data provided in-context, particularly when solely essentially the most related materials is offered, so a very good retrieval system is essential.
Word that the selection of the embedding mannequin used for RAG is crucial. It’s not part of the database and selecting the right embedding mannequin on your utility is vital for attaining good efficiency. Moreover, whereas new and improved fashions are consistently being launched, altering to a brand new mannequin requires reindexing your complete database.
Evaluating Your Choices
Selecting a database in an enterprise atmosphere will not be a simple activity. A database is usually the guts of your software program infrastructure that manages a vital enterprise asset: knowledge.
Usually, once we select a database we would like:
- Dependable storage
- Environment friendly querying
- Capacity to insert, replace, and delete knowledge granularly (CRUD)
- Arrange a number of customers with varied ranges of entry for them (RBAC)
- Knowledge consistency (predictable conduct when modifying knowledge)
- Capacity to recuperate from failures
- Scalability to the dimensions of our knowledge
This record will not be exhaustive and could be a bit apparent, however not all new vector databases have these options. Typically, it’s the availability of enterprise options that decide the ultimate selection between a widely known mature database that gives vector search through extensions and a more recent vector-only database.
Vector-only databases have native assist for vector search and might execute queries very quick, however typically lack enterprise options and are comparatively immature. Take into account that it takes years to construct complicated options and battle-test them, so it’s no shock that early adopters face outages and knowledge losses. However, in current databases that present vector search by extensions, a vector will not be a first-class citizen and question efficiency could be a lot worse.
We’ll categorize all present databases that present vector search into the next teams after which focus on them in additional element:
- Vector search libraries
- Vector-only databases
- NoSQL databases with vector search
- SQL databases with vector search
- Vector search options from cloud distributors
Vector search libraries
Vector search libraries like FAISS and ANNOY usually are not databases – moderately, they supply in-memory vector indices, and solely restricted knowledge persistence choices. Whereas these options usually are not excellent for customers requiring a full enterprise database, they’ve very quick nearest neighbor search and are open supply. They provide good assist for high-dimensional knowledge and are extremely configurable (you possibly can select the index kind and different parameters).
Total, they’re good for prototyping and integration in easy purposes, however they’re inappropriate for long-term, multi-user knowledge storage.
Vector-only databases
This group contains numerous merchandise like Milvus, Chroma, Pinecone, Weaviate, and others. There are notable variations amongst them, however all of them are particularly designed to retailer and retrieve vectors. They’re optimized for environment friendly similarity search with indexing and assist high-dimensional knowledge and vector operations natively.
Most of them are newer and won’t have the enterprise options we talked about above, e.g. a few of them don’t have CRUD, no confirmed failure restoration, RBAC, and so forth. For essentially the most half, they’ll retailer the uncooked knowledge, the embedding vector, and a small quantity of metadata, however they’ll’t retailer different index sorts or relational knowledge, which implies you’ll have to use one other, secondary database and keep consistency between them.
Their efficiency is usually unmatched and they’re a very good choice when having multimodal knowledge (photos, audio or video).
NoSQL databases with vector search
Many so-called NoSQL databases not too long ago added vector search to their merchandise, together with MongoDB, Redis, neo4j, and ElasticSearch. They provide good enterprise options, are mature, and have a robust group, however they supply vector search performance through extensions which could result in lower than excellent efficiency and lack of first-class assist for vector search. Elasticsearch stands out right here as it’s designed for full-text search and already has many conventional data retrieval options that can be utilized along with vector search.
NoSQL databases with vector search are a sensible choice if you end up already invested in them and wish vector search as a further, however not very demanding characteristic.
SQL databases with vector search
This group is considerably much like the earlier group, however right here we have now established gamers like PostgreSQL and ClickHouse. They provide a big selection of enterprise options, are well-documented, and have sturdy communities. As for his or her disadvantages, they’re designed for structured knowledge, and scaling them requires particular experience.
Their use case can be comparable: good selection when you have already got them and the experience to run them in place.
Vector search options from cloud distributors
Hyperscalers additionally provide vector search companies. They normally have primary options for vector search (you possibly can select an embedding mannequin, index kind, and different parameters), good interoperability inside the remainder of the cloud platform, and extra flexibility on the subject of price, particularly for those who use different companies on their platform. Nevertheless, they’ve completely different maturity and completely different characteristic units: Google Cloud vector search makes use of a quick proprietary index search algorithm known as ScaNN and metadata filtering, however will not be very user-friendly; Azure Vector search affords structured search capabilities, however is in preview part and so forth.
Vector search entities could be managed utilizing enterprise options of their platform like IAM (Id and Entry Administration), however they don’t seem to be that straightforward to make use of and suited to normal cloud utilization.
Making the Proper Selection
The primary use case of vector databases on this context is to supply related data to a mannequin. On your subsequent LLM challenge, you possibly can select a database from an current array of databases that supply vector search capabilities through extensions or from new vector-only databases that supply native vector assist and quick querying.
The selection relies on whether or not you want enterprise options, or high-scale efficiency, in addition to your deployment structure and desired maturity (analysis, prototyping, or manufacturing). One also needs to think about which databases are already current in your infrastructure and whether or not you have got multimodal knowledge. In any case, no matter selection you’ll make it’s good to hedge it: deal with a brand new database as an auxiliary storage cache, moderately than a central level of operations, and summary your database operations in code to make it straightforward to regulate to the subsequent iteration of the vector RAG panorama.
How DataRobot Can Assist
There are already so many vector database choices to select from. They every have their execs and cons – nobody vector database will likely be proper for your whole group’s generative AI use instances. That’s the reason it’s vital to retain optionality and leverage an answer that lets you customise your generative AI options to particular use instances, and adapt as your wants change or the market evolves.
The DataRobot AI Platform permits you to carry your personal vector database – whichever is true for the answer you’re constructing. If you happen to require modifications sooner or later, you possibly can swap out your vector database with out breaking your manufacturing atmosphere and workflows.
In regards to the writer
Nick Volynets is a senior knowledge engineer working with the workplace of the CTO the place he enjoys being on the coronary heart of DataRobot innovation. He’s excited about giant scale machine studying and captivated with AI and its influence.