Phase two of Google’s mobile-first indexing – rendering – is Chrome and has been since 2018, according to SEO expert Cindy Krum. In a newly released video presentation, Krum said:
- “What I believe is happening here is that Google failed to tell us at this time in 2018, when it launched, that what they were using for the second phase of indexing was not a bot, per se. It was our own computers in our homes. Your Chrome being used as a rendering resource became available. That means you. As someone requested the site and executed the JavaScript, they would go and fetch that from their computer. They wouldn’t use their bot to render it. They would wait until a user rendered the page for them and then they would just go capture that full-page render so that they could process it.
- “… Google [is] using our own computers to pre-process information for indexing and our own browsers to capture information and rendering. We haven’t necessarily opted into this and we’re not knowingly getting anything back.
- “…Google is also using our rendering data and our behavior – in terms of making models like cohort models and topic models, history and engagement models – and they’re using this all taking it from our local computers without permission and passing it up to their processors. Now it’s pre-processed locally so that it can be batched and sent up and then sending it to their algorithms to be further processed and evaluated. That’s how they’re able to get the rankings that they do, but also that’s how they’re able to understand things like demographic cohorts, Journeys, where you shop, and make decisions and understanding and modeling that so that they can use that data in their advertising models in PMax, in PPC campaigns. They’re using our own behavior to market to us and to train AI that serves ads to do a better job.”
Put simply in two slides:
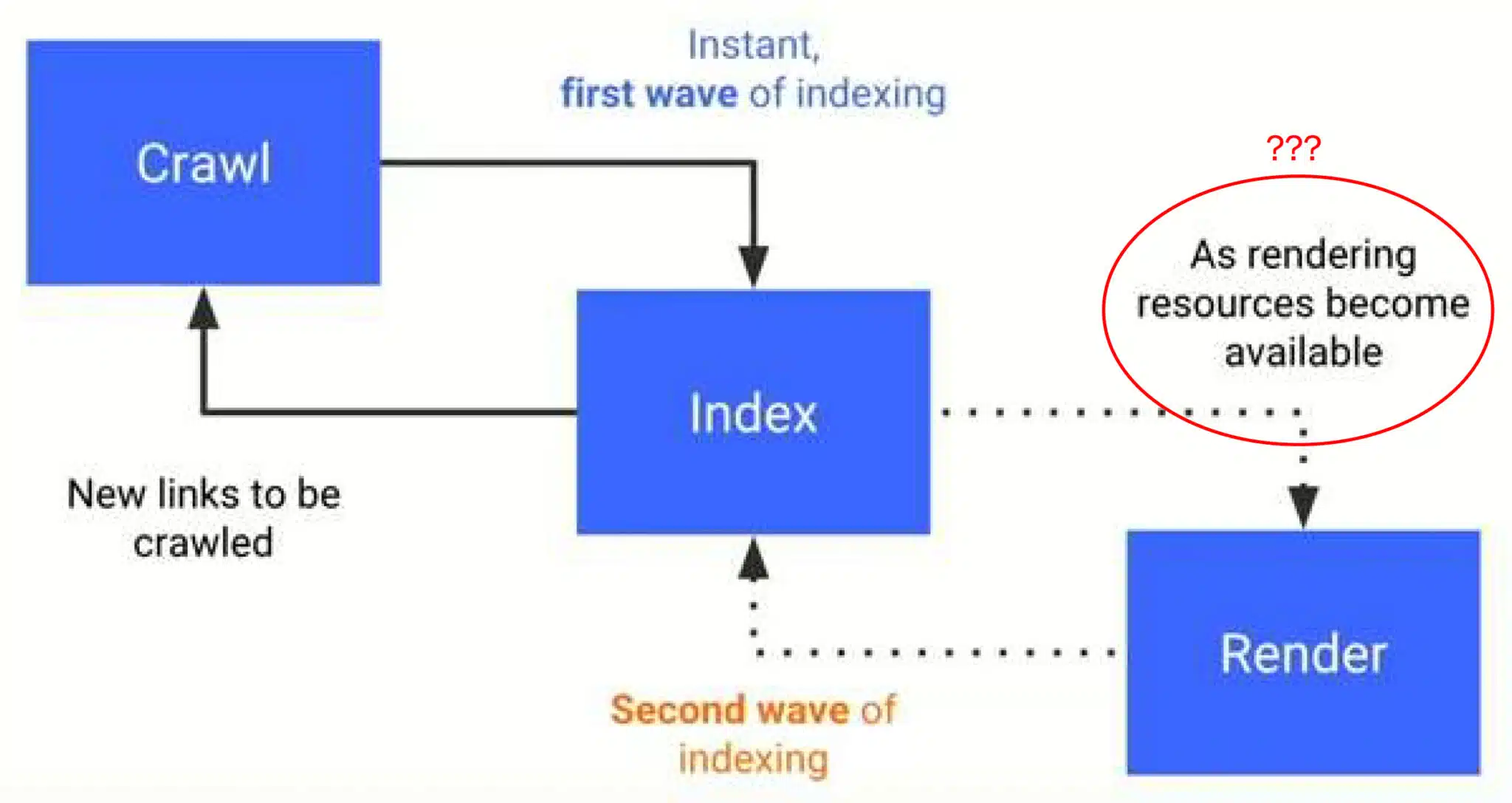
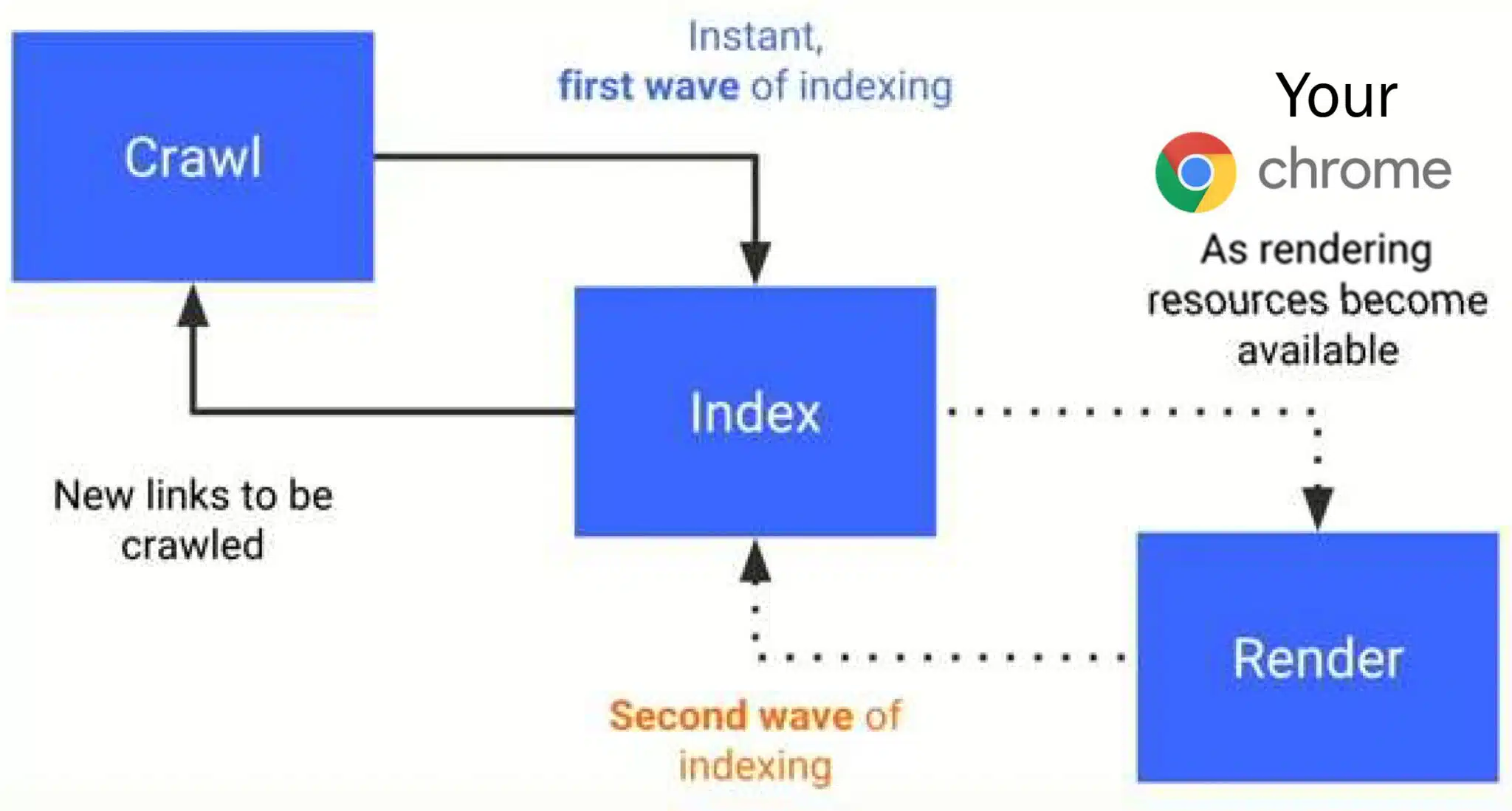
Connecting dots. There are a lot of claims made about other huge implications of Google’s switch to mobile-first indexing in Krum’s presentation, as well as how Chrome essentially fuels Google’s illegal search monopoly:
- User computers as resources: Google uses users’ devices to render and process JavaScript, which they then index – essentially outsourcing computational work to users. Essentially, Google is using Chrome in the same way your computer could be used for Bitcoin mining.
- Core Web Vitals: Google captures real user data to assess page load performance and interaction and feeds this data into its ranking algorithms.
- Browser updates and data collection: Frequent Chrome updates ensure data collection aligns with Google’s search and ad models, contributing to targeted advertising and AI training.
- Privacy violations: Google has been found indexing private data (e.g., private WhatsApp groups), likely due to its aggressive caching and data collection practices.
- Chrome’s role in AI: AI is very expensive, so Google could use Chrome’s processing model to help with AI development, giving them an edge in the AI arms race.
- Ad tracking and targeting: Google’s data collection extends into advertising models like cohort targeting and user behavior modeling for ad optimization.
- Cookies and privacy: Despite promising to end third-party cookies, Google continues to use them for extensive tracking and data collection.
Possible SEO implications. I reached out to Krum and asked her what the possible SEO implications are here if all of this is correct. She told me:
- If a page has links that never get clicked, Google is less likely to crawl it. We knew this, in theory, but now we have a better idea of how it works.
- Real user engagement is likely factoring in more than previously thought – we have known this since the Google Search leak.
- Manipulation of SERP and click information is a significant vulnerability, if it happens in Chrome.
- Actual user rendering is critical, so selective serving for GoogleBot might not be a great strategy.
Why we care. We know that Google collects extensive Chrome and end-user data from its other various services (Search, YouTube, Ads, etc.). That said, and to be clear, much of what she discusses is for now an unconfirmed theory (Krum does use the word “tinfoil” during her presentation and there are multiple “X-Files” themed slides).
When I first watched the video, I found it equal parts fantastical, inconceivable and entirely believable. It’s a lot to process. However, in light of all the revelations from the DOJ trial and the leak, nothing Krum discusses in the video seems like too wild of speculation. I’ll be curious to see whether Google responds.
Additional reading. Krum also referenced research by Malte Ubl, a former Googler, who said that “Google uses an up-to-date version of Chrome for rendering” and whose research found that “100% of HTML pages resulted in full-page renders, including pages with complex JS interactions.”
The presentation. Watch the video and decide for yourself (I suggest starting around 6:37): Phase II of Google’s Mobile-First Indexing is just Chrome.