Reinforcement studying supplies a conceptual framework for autonomous brokers to be taught from expertise, analogously to how one may prepare a pet with treats. However sensible purposes of reinforcement studying are sometimes removed from pure: as a substitute of utilizing RL to be taught by means of trial and error by really making an attempt the specified activity, typical RL purposes use a separate (often simulated) coaching section. For instance, AlphaGo didn’t be taught to play Go by competing in opposition to hundreds of people, however reasonably by taking part in in opposition to itself in simulation. Whereas this sort of simulated coaching is interesting for video games the place the principles are completely recognized, making use of this to actual world domains akin to robotics can require a spread of advanced approaches, akin to the usage of simulated information, or instrumenting real-world environments in numerous methods to make coaching possible beneath laboratory situations. Can we as a substitute devise reinforcement studying techniques for robots that permit them to be taught straight “on-the-job”, whereas performing the duty that they’re required to do? On this weblog publish, we’ll focus on ReLMM, a system that we developed that learns to scrub up a room straight with an actual robotic by way of continuous studying.




We consider our technique on completely different duties that vary in issue. The highest-left activity has uniform white blobs to pickup with no obstacles, whereas different rooms have objects of numerous shapes and colours, obstacles that improve navigation issue and obscure the objects and patterned rugs that make it troublesome to see the objects in opposition to the bottom.
To allow “on-the-job” coaching in the actual world, the issue of gathering extra expertise is prohibitive. If we will make coaching in the actual world simpler, by making the information gathering course of extra autonomous with out requiring human monitoring or intervention, we will additional profit from the simplicity of brokers that be taught from expertise. On this work, we design an “on-the-job” cellular robotic coaching system for cleansing by studying to know objects all through completely different rooms.
Individuals are not born at some point and performing job interviews the following. There are various ranges of duties folks be taught earlier than they apply for a job as we begin with the simpler ones and construct on them. In ReLMM, we make use of this idea by permitting robots to coach common-reusable abilities, akin to greedy, by first encouraging the robotic to prioritize coaching these abilities earlier than studying later abilities, akin to navigation. Studying on this trend has two benefits for robotics. The primary benefit is that when an agent focuses on studying a talent, it’s extra environment friendly at gathering information across the native state distribution for that talent.
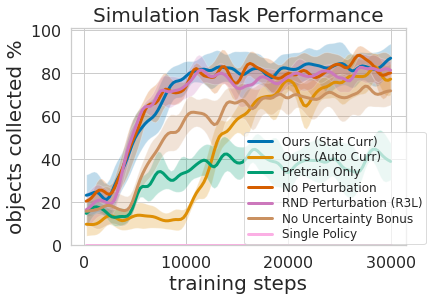
That’s proven within the determine above, the place we evaluated the quantity of prioritized greedy expertise wanted to end in environment friendly cellular manipulation coaching. The second benefit to a multi-level studying strategy is that we will examine the fashions educated for various duties and ask them questions, akin to, “are you able to grasp something proper now” which is useful for navigation coaching that we describe subsequent.
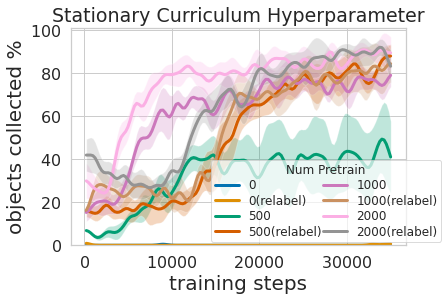
Coaching this multi-level coverage was not solely extra environment friendly than studying each abilities on the identical time but it surely allowed for the greedy controller to tell the navigation coverage. Having a mannequin that estimates the uncertainty in its grasp success (Ours above) can be utilized to enhance navigation exploration by skipping areas with out graspable objects, in distinction to No Uncertainty Bonus which doesn’t use this info. The mannequin will also be used to relabel information throughout coaching in order that within the unfortunate case when the greedy mannequin was unsuccessful making an attempt to know an object inside its attain, the greedy coverage can nonetheless present some sign by indicating that an object was there however the greedy coverage has not but discovered tips on how to grasp it. Furthermore, studying modular fashions has engineering advantages. Modular coaching permits for reusing abilities which can be simpler to be taught and might allow constructing clever techniques one piece at a time. That is useful for a lot of causes, together with security analysis and understanding.
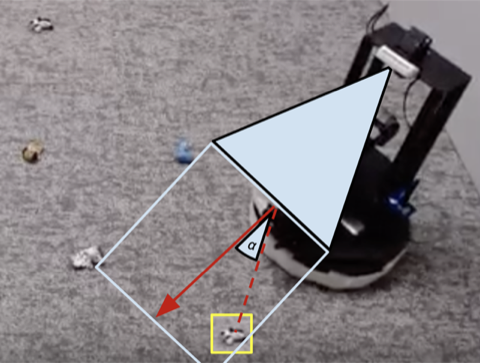
Many robotics duties that we see as we speak could be solved to various ranges of success utilizing hand-engineered controllers. For our room cleansing activity, we designed a hand-engineered controller that locates objects utilizing picture clustering and turns in the direction of the closest detected object at every step. This expertly designed controller performs very effectively on the visually salient balled socks and takes cheap paths across the obstacles but it surely cannot be taught an optimum path to gather the objects shortly, and it struggles with visually numerous rooms. As proven in video 3 beneath, the scripted coverage will get distracted by the white patterned carpet whereas making an attempt to find extra white objects to know.
1) 
2) 
3) 
4) 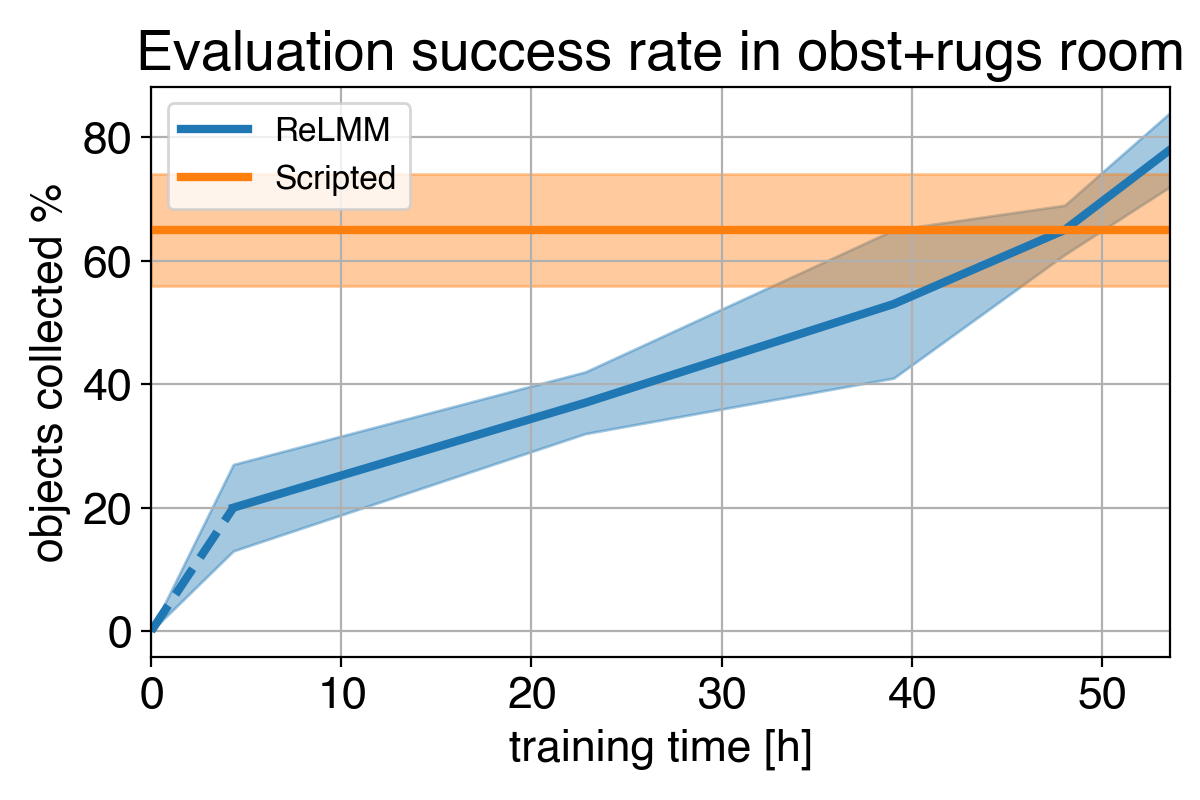
We present a comparability between (1) our coverage initially of coaching (2) our coverage on the finish of coaching (3) the scripted coverage. In (4) we will see the robotic’s efficiency enhance over time, and finally exceed the scripted coverage at shortly gathering the objects within the room.
Given we will use consultants to code this hand-engineered controller, what’s the goal of studying? An essential limitation of hand-engineered controllers is that they’re tuned for a selected activity, for instance, greedy white objects. When numerous objects are launched, which differ in shade and form, the unique tuning might not be optimum. Quite than requiring additional hand-engineering, our learning-based technique is ready to adapt itself to varied duties by gathering its personal expertise.
Nevertheless, a very powerful lesson is that even when the hand-engineered controller is succesful, the training agent finally surpasses it given sufficient time. This studying course of is itself autonomous and takes place whereas the robotic is performing its job, making it comparatively cheap. This reveals the aptitude of studying brokers, which will also be regarded as figuring out a basic approach to carry out an “professional handbook tuning” course of for any sort of activity. Studying techniques have the flexibility to create the complete management algorithm for the robotic, and usually are not restricted to tuning a couple of parameters in a script. The important thing step on this work permits these real-world studying techniques to autonomously gather the information wanted to allow the success of studying strategies.
This publish is predicated on the paper “Absolutely Autonomous Actual-World Reinforcement Studying with Purposes to Cell Manipulation”, offered at CoRL 2021. You’ll find extra particulars in our paper, on our web site and the on the video. We offer code to breed our experiments. We thank Sergey Levine for his helpful suggestions on this weblog publish.