Crowd-sourced human high quality raters have been the mainstay of the algorithmic analysis course of for search engines like google for many years. Nonetheless, a possible sea-change in analysis and manufacturing implementation could possibly be on the horizon.
Current groundbreaking analysis by Bing (with some purported business implementation already) and a pointy uptick in intently associated info retrieval analysis by others, signifies some large shake-ups are coming.
These shake-ups could have far-reaching penalties for each the armies of high quality raters and probably the frequency of algorithmic updates we see go stay, too.
The significance of analysis
Along with crawling, indexing, rating and consequence serving for search engines like google is the necessary technique of analysis.
How effectively does a present or proposed search consequence set or experimental design align with the notoriously subjective notion of relevance to a given question, at a given time, for a given search engine person’s contextual info wants?
Since we all know relevance and intent for a lot of queries are all the time altering, and the way customers choose to devour info evolves, search consequence pages additionally want to alter to satisfy each the searcher’s intent and most popular person interface.
Some modifications have predictable, temporal and periodic question intent shifts. For instance, within the interval approaching Black Friday, many queries sometimes thought of informational may take sweeping business intent shifts. Equally, a transport question like [Liverpool Manchester] may shift to a sports activities question on native match derby days.
In these cases, an ever-expanding legacy of historic knowledge helps a excessive chance of what customers take into account extra significant outcomes, albeit briefly. These ranges of confidence probably make seasonal or different predictable periodic outcomes and non permanent UI design shifting comparatively simple changes for search engines like google to implement.
Nevertheless, relating to broader notions of evolving “relevance” and “high quality,” and for the needs of experimental design modifications too, search engines like google should know a proposed change in rankings after growth by search engineers is actually higher and extra exact to info wants, than the current outcomes generated.
Analysis is a vital stage in search outcomes evolution and important to offering confidence in proposed modifications – and substantial knowledge for any changes (algorithmic tuning) to the proposed “methods,” if required.
Analysis is the place people “enter the loop” (offline and on-line) to offer suggestions in varied methods earlier than roll-outs to manufacturing environments.
This isn’t to say analysis isn’t a steady a part of manufacturing search. It’s. Nevertheless, an ongoing judgment of present outcomes and person exercise will probably consider how effectively an carried out change continues to fare in manufacturing in opposition to a suitable relevance (or satisfaction) primarily based metric vary. A metric vary primarily based on the preliminary human judge-submitted relevance evaluations.
In a 2022 paper titled, “The group is made of individuals: Observations from large-scale crowd labelling,” Thomas et al., who’re researchers from Bing, allude to the continued use of such metric ranges in a manufacturing setting when referencing a monitored part of internet search “evaluated partially by RBP-based scores, calculated each day over tens of 1000’s of judge-submitted labels.” (RBP stands for Rank-Biased Precision).
Human-in-the-loop (HITL)
Information labels and labeling
An necessary level earlier than we proceed. I’ll point out labels and labeling quite a bit all through this piece, and a clarification about what is supposed by labels and labeling will make the remainder of this text a lot simpler to grasp:
I’ll give you a few real-world examples most individuals might be accustomed to for breadth of viewers understanding earlier than persevering with:
- Have you ever ever checked a Gmail account and marked one thing as spam?
- Have you ever ever marked a movie on Netflix as “Not for me,” “I like this,” or “love this”?
All of those submitted actions by you create knowledge labels utilized by search engines like google or in info retrieval methods. Sure, even Netflix has an enormous basis in info retrieval and an important info retrieval analysis staff device. (Observe that Netflix is each info retrieval with a powerful subset of that discipline, referred to as “recommender methods.”)
By marking “Not for me” on a Netflix movie, you submitted a knowledge label. You turned a knowledge labeler to assist the “system” perceive extra about what you want (and in addition what individuals just like you want) and to assist Netflix practice and tune their recommender methods additional.
Information labels are throughout us. Labels markup knowledge so it may be remodeled into mathematical types for measurement at scale.
Huge quantities of those labels and “labeling” within the info retrieval and machine studying area are used as coaching knowledge for machine studying.
“This picture has been labeled as a cat.”
“This picture has been labeled as a canine… cat… canine… canine… canine… cat,” and so forth.
The entire labels assist machines be taught what a canine or a cat appears like with sufficient examples of photographs marked as cats or canine.
Labeling isn’t new; it’s been round for hundreds of years, for the reason that first classification of things befell. A label was assigned when one thing was marked as being in a “subset” or “set of issues.”
Something “labeled” has successfully had a label hooked up to it, and the one that marked the merchandise as belonging to that specific classification is taken into account the labeler.
However shifting ahead to current instances, most likely the best-known knowledge labeling instance is that of reCAPTCHA. Each time we choose the little squares on the picture grid, we add labels, and we’re labelers.
We, as people, “enter the loop” and supply suggestions and knowledge.
With that rationalization out of the way in which, allow us to transfer on to the other ways knowledge labels and suggestions are acquired, and specifically, suggestions for “relevance” to queries to tune algorithms or consider experimental design by search engines like google.
Implicit and express analysis suggestions
Whereas Google refers to their analysis methods in paperwork meant for the non-technical viewers general as “rigorous testing,” human-in-the-loop evaluations in info retrieval broadly occur by way of implicit or express suggestions.
Implicit suggestions
With implicit suggestions, the person isn’t actively conscious they supply suggestions. The numerous stay search visitors experiments (i.e., checks within the wild) search engines like google perform on tiny segments of actual customers (as small as 0.1%), and subsequent evaluation of click on knowledge, person scrolling, dwell time and consequence skipping, fall into the class of implicit suggestions.
Along with stay experiments, the continued normal click on, scroll and browse conduct of actual search engine customers can even represent implicit suggestions and certain feed into “Studying to Rank (LTR) machine studying” click on fashions.
This, in flip, feeds into rationales for proposed algorithmic relevance modifications, as non-temporal searcher conduct shifts and world modifications result in unseen queries and new meanings for queries.
There may be the age-old search engine optimization debate round whether or not rankings change instantly earlier than additional analysis from implicit click on knowledge. I can’t cowl that right here apart from to say there’s appreciable consciousness of the large bias and noise that comes with uncooked click on knowledge within the info retrieval analysis area and the large challenges in its steady use in stay environments. Therefore, the various items of analysis work round proposed click on fashions for unbiased studying to rank and studying to rank with bias.
Regardless, it’s no secret general in info retrieval how necessary click on knowledge is for analysis functions. There are numerous papers and even IR books co-authored by Google analysis staff members, corresponding to “Click on Fashions for Internet Search” (Chuklin and De Rijke, 2022).
Google additionally brazenly states of their “rigorous testing” article:
“We have a look at a really lengthy record of metrics, corresponding to what individuals click on on, what number of queries have been achieved, whether or not queries have been deserted, how lengthy it took for individuals to click on on a consequence and so forth.”
And so a cycle continues. Detected change wanted from Studying to Rank, click on mannequin utility, engineering, analysis, detected change wanted, click on mannequin utility, engineering, analysis, and so forth.
Specific suggestions
In distinction to implicit suggestions from unaware search engine customers (in stay experiments or typically use), express suggestions is derived from actively conscious members or relevance labelers.
The aim of this relevance knowledge assortment is to mathematically roll it up and modify general proposed methods.
A gold customary of relevance labeling – thought of close to to a floor reality (i.e., the fact of the true world) of intent to question matching – is in the end sought.
There are numerous methods during which a gold customary of relevance labeling is gathered. Nevertheless, a silver customary (much less exact than gold however extra broadly obtainable knowledge) is usually acquired (and accepted) and certain used to help in additional tuning.
Specific suggestions takes 4 most important codecs. Every has its benefits and downsides, largely about relevance labeling high quality (in contrast with gold customary or floor reality) and the way scalable the method is.
Actual customers in suggestions periods with person suggestions groups
Search engine person analysis groups and actual customers supplied with totally different contexts in numerous international locations collaborate in person suggestions periods to offer relevance knowledge labels for queries and their intents.
This format probably supplies close to to a gold customary of relevance. Nevertheless, the strategy isn’t scalable on account of its time-consuming nature, and the variety of members might by no means be anyplace close to consultant of the broader search inhabitants at giant.
True subject material consultants / subject consultants / skilled annotators
True subject material consultants {and professional} relevance assessors present relevance for question mappings annotated to their intents in knowledge labeling, together with many nuanced instances.
Since these are the authors of the question to intent mappings, they know the precise intent, and any such labeling is probably going thought of close to to a gold customary. Nevertheless, this methodology, just like the person suggestions analysis groups format, isn’t scalable because of the sparsity of relevance labels and, once more, the time-consuming nature of this course of.
This methodology was extra broadly used earlier than introducing the extra scalable method of crowd-sourced human high quality raters (to observe) in current instances.
Serps merely ask actual customers whether or not one thing is related or useful
Actual search engine customers are actively requested whether or not a search result’s useful (or related) by search engines like google and consciously present express binary suggestions within the type of sure or no responses with current “thumbs up” design modifications noticed within the wild.
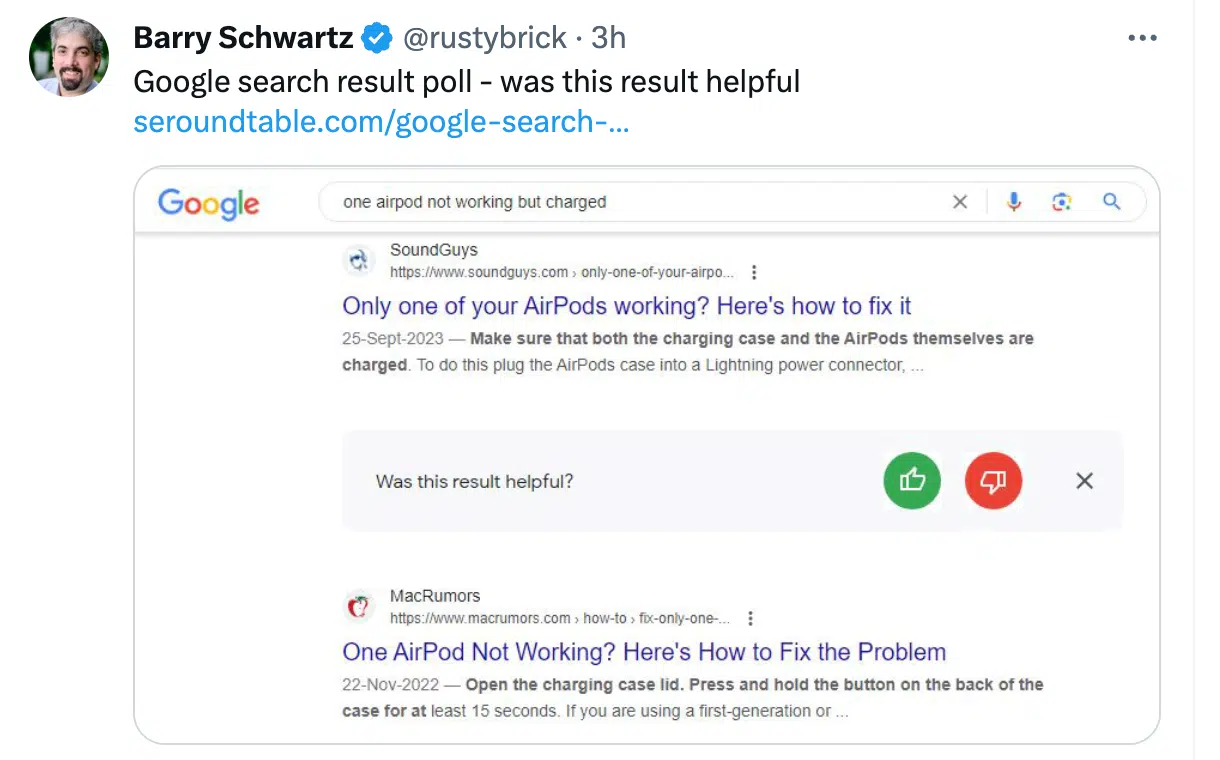
Crowd-sourced human high quality raters
The principle supply of express suggestions comes from “the gang.” Main search engines like google have enormous numbers of crowd-sourced human high quality raters supplied with some coaching and handbooks and employed by way of exterior contractors working remotely worldwide.
Google alone has a purported 16,000 such high quality raters. These crowd-sourced relevance labelers and the packages they’re a part of are referred to in another way by every search engine.
Google refers to its members as “high quality raters” within the High quality Raters Program, with the third-party contractor referring to Google’s internet search relevance program as “Challenge Yukon.”
Bing refers to their members as merely “judges” within the Human Relevance System (HRS), with third-party contractors referring to Bing’s undertaking as merely “Internet Content material Assessor.”
Regardless of these variations, members’ functions are primarily the identical. The position of the crowd-sourced human high quality rater is to offer artificial relevance labels emulating search engine customers the world over as a part of express algorithmic suggestions. Suggestions usually takes the type of a side-by-side (pairwise) comparability of proposed modifications versus both present methods or alongside different proposed system modifications.
Since a lot of that is thought of offline analysis, it isn’t all the time stay search outcomes which can be being in contrast but additionally photographs of outcomes. And it isn’t all the time a pairwise comparability, both.
These are simply among the many various kinds of duties that human high quality raters perform for analysis, and knowledge labeling, by way of third-party contractors. The relevance judges probably repeatedly monitor after the proposed change roll-out to manufacturing search, too. (For instance, because the aforementioned Bing analysis paper alludes to.)
Regardless of the methodology of suggestions acquisition, human-in-the-loop relevance evaluations (both implicit or express) play a major position earlier than the various algorithmic updates (Google launched over 4,700 modifications in 2022 alone, for instance), together with the now more and more frequent broad core updates, which in the end seem like an general analysis of elementary relevance revisited.
Get the each day e-newsletter search entrepreneurs depend on.
Relevance labeling at a question degree and a system degree
Regardless of the weblog posts we now have seen alerting us to the scary prospect of human high quality raters visiting our web site by way of referral visitors evaluation, naturally, in methods constructed for scale, particular person outcomes of high quality rater evaluations at a web page degree, and even at a person rater degree haven’t any significance on their very own.
Human high quality raters don’t decide web sites or webpages in isolation
Analysis is a measurement of methods, not internet pages – with “methods” that means the algorithms producing the proposed modifications. The entire relevance labels (i.e., “related,” “not related,” “extremely related”) supplied by labelers roll as much as a system degree.
“We use responses from raters to guage modifications, however they don’t immediately impression how our search outcomes are ranked.”
– “How our High quality Raters make Search outcomes higher,” Google Search Assist
In different phrases, whereas relevance labeling doesn’t immediately impression rankings, aggregated knowledge labeling does present a way to take an general (common) measurement of how effectively a proposed algorithmic change (system) is likely to be, extra exactly related (when ranked), with a lot of reliance on varied kinds of algorithmic averages.
Question-level scores are mixed to find out system-level scores. Information from relevance labels is changed into numerical values after which into “common” precision metrics to “tune” the proposed system additional earlier than any roll-out to go looking engine customers extra broadly.
How removed from the anticipated common precision metrics engineers hoped to attain with the proposed change is the fact when ‘people enter the loop’?
Whereas we can’t be fully positive of the metrics used on aggregated knowledge labels when all the things is changed into numerical values for relevance measurement, there are universally acknowledged info retrieval rating analysis metrics in lots of analysis papers.
Most authors of such papers are search engine engineers, lecturers, or each. Manufacturing follows analysis within the info retrieval discipline, of which all internet search is a component.
Such metrics are order-aware analysis metrics (the place the ranked order of relevance issues, and weighting, or “punishing” of the analysis if the ranked-order is wrong). These metrics embody:
- Imply reciprocal rank (MRR).
- Rank-biased precision (RBP).
- Imply common precision (MAP).
- Normalized and un-normalized discounted cumulative acquire (NDCG and DCG respectively).
In a 2022 analysis paper co-authored by a Google analysis engineer, NDCG and AP (common precision) are known as a norm within the analysis of pairwise rating outcomes:
“A elementary step within the offline analysis of search and advice methods is to find out whether or not a rating from one system tends to be higher than the rating of a second system. This usually entails, given item-level relevance judgments, distilling every rating right into a scalar analysis metric, corresponding to common precision (AP) or normalized discounted cumulative acquire (NDCG). We will then say that one system is most popular to a different if its metric values are typically greater.”
– “Offline Retrieval Analysis With out Analysis Metrics,” Diaz and Ferraro, 2022
Data on DCG, NDCG, MAP, MRR and their commonality of use in internet search analysis and rating tuning is broadly obtainable.
Victor Lavrenko, a former assistant professor on the College of Edinburgh, additionally describes one of many extra frequent analysis metrics, imply common precision, effectively:
“Imply Common Precision (MAP) is the usual single-number measure for evaluating search algorithms. Common precision (AP) is the typical of … precision values in any respect ranks the place related paperwork are discovered. AP values are then averaged over a big set of queries…”
So it’s actually all concerning the averages judges submit from the curated knowledge labels distilled right into a consumable numerical metric versus the expected averages hoped for after engineering after which tuning the rating algorithms additional.
High quality raters are merely relevance labelers
High quality raters are merely relevance labelers, classifying and feeding an enormous pipeline of knowledge, rolled up and changed into numerical scores for:
- Aggregation on whether or not a proposed change is close to a suitable common degree of relevance precision or person satisfaction.
- Or figuring out whether or not the proposed change wants additional tuning (or complete abandonment).
The sparsity of relevance labeling causes a bottleneck
Whatever the analysis metrics used, the preliminary knowledge is an important a part of the method (the relevance labels) since, with out labels, no measurement by way of analysis can happen.
A rating algorithm or proposed change is all very effectively, however until “people enter the loop” and decide whether or not it’s related in analysis, the change probably received’t occur.
For the previous couple of a long time, in info retrieval broadly, the primary pipeline of this HITL-labeled relevance knowledge has come from crowd-sourced human high quality raters, which changed the usage of the skilled (however fewer in numbers) skilled annotators as search engines like google (and their want for fast iteration) grew.
Feeding yays and nays in flip transformed into numbers and averages so as to tune search methods.
However scale (and the necessity for increasingly relevance labeled knowledge) is more and more problematic, and never only for search engines like google (even regardless of these armies of human high quality raters).
The scalability and sparsity concern of knowledge labeling presents a worldwide bottleneck and the basic “demand outstrips provide” problem.
Widespread demand for knowledge labeling has grown phenomenally because of the explosion in machine studying in lots of industries and markets. Everybody wants tons and many knowledge labeling.
Current analysis by consulting agency Grand View Analysis illustrates the large progress in market demand, reporting:
“The worldwide knowledge assortment and labeling market dimension was valued at $2.22 billion in 2022 and it’s anticipated to increase at a compound annual progress price of 28.9% from 2023 to 2030, with the market then anticipated to be price $13.7 billion.”
That is very problematic. Notably in more and more aggressive arenas corresponding to AI-driven generative search with the efficient coaching of enormous language fashions requiring enormous quantities of labeling and annotations of many varieties.
Authors at Deepmind, in a 2022 paper, state:
“We discover present giant language fashions are considerably undertrained, a consequence of the current give attention to scaling language fashions whereas maintaining the quantity of coaching knowledge fixed. …we discover for compute-optimal coaching …for each doubling of mannequin dimension the variety of coaching tokens must also be doubled.”
– “Coaching Compute-Optimum Giant Language Fashions,” Hoffman et al.
When the quantity of labels wanted grows faster than the gang can reliably produce them, a bottleneck in scalability for relevance and high quality by way of speedy analysis on manufacturing roll-outs can happen.
Lack of scalability and sparsity don’t match effectively with speedy iterative progress
Lack of scalability was a problem when search engines like google moved away from the business norm {of professional}, skilled annotators and towards the crowd-sourced human high quality raters offering relevance labels, and scale and knowledge sparsity is as soon as once more a significant concern with the established order of utilizing the gang.
Some issues with crowd-sourced human high quality raters
Along with the shortage of scale, different points include utilizing the gang. A few of these relate to human nature, human error, moral concerns and reputational issues.
Whereas relevance stays largely subjective, crowd-sourced human high quality raters are supplied with, and examined on, prolonged handbooks, so as to decide relevance.
Google’s publicly obtainable High quality Raters Information is over 160 pages lengthy, and Bing’s Human Relevance Pointers is “reported to be over 70 pages lengthy,” per Thomas et al.
Bing is far more coy with their relevance coaching handbooks. Nonetheless, when you root round, as I did when researching this piece, you could find among the documentation with unbelievable element on what relevance means (on this occasion for native search), which appears like one in every of their judging pointers within the depths on-line.
Efforts are made on this coaching to instill a mindset appreciative of the evaluator’s position as a “pseudo” search engine person of their pure locale.
The artificial person mindset wants to contemplate many components when emulating actual customers with totally different info wants and expectations.
These wants and expectations depend upon a number of components past merely their locale, together with age, race, faith, gender, private opinion and political affiliation.
The group is made of individuals
Unsurprisingly, people will not be with out their failings as relevance knowledge labelers.
Human error wants no rationalization in any respect and bias on the net is a recognized concern, not only for search engines like google however extra usually in search, machine studying, and AI general. Therefore, the devoted “accountable AI” discipline emerges partially to cope with combatting baked-in biases in machine studying and algorithms.
Nevertheless, findings within the 2022 large-scale research by Thomas et al., Bing researchers, spotlight components resulting in decreased precision relevance labeling going past easy human error and conventional aware or unconscious bias.
Even regardless of the coaching and handbooks, Bing’s findings, derived from “tons of of hundreds of thousands of labels, collected from tons of of 1000’s of employees as a routine a part of search engine growth,” underscore among the much less apparent components, extra akin to physiological and cognitive components and contributing to a discount in precision high quality in relevance labeling duties, and may be summarised as follows:
- Job-switching: Corresponded immediately with a decline in high quality of relevance labeling, which was vital as solely 28% of members labored on a single job in a session with all others shifting between duties.
- Left facet bias: In a side-by-side comparability, a consequence displayed on the left facet was extra more likely to be chosen as related compared with outcomes on the proper facet. Since pair-wise evaluation by search engines like google is widespread, that is regarding.
- Anchoring: Performed an element in relevance labeling decisions, whereby the relevance label assigned on the primary consequence by a labeler can also be more likely to be the relevance label assigned for the second consequence. This identical label choice appeared to have a descending chance of choice within the first 10 evaluated queries in a session. After 10 evaluated queries, the researchers discovered that the anchoring concern appeared to vanish. On this occasion the labeler hooks (anchors) onto the primary selection they make and since they haven’t any actual notion of relevance or context at the moment, the chance of them selecting the identical relevance label with the subsequent choice is excessive. This phenomenon disappears because the labeler gathers extra info from subsequent pairwise units to contemplate.
- Normal fatigue of crowd-workers performed an element in decreased precision labeling.
- Normal disagreement between judges on which one in every of a pairwise consequence was related from the 2 choices. Merely differing opinions and maybe a scarcity of true understanding of the context of the meant search engine person.
- Time of day and day of week when labeling was carried out by evaluators additionally performs a task. The researchers famous some associated findings which appeared to correlate with spikes in decreased relevance labeling accuracy when regional celebrations have been underway, and might need simply been thought of easy human error, or noise, if not explored extra totally.
The group isn’t good in any respect.
A darkish facet of the info labeling business
Then there’s the opposite facet of the usage of human crowd-sourced labelers, which issues society as a complete. That of low-paid “ghost employees” in rising economies employed to label knowledge for search engines like google and others within the tech and AI business.
Main on-line publications more and more draw consideration to this concern with headlines like:
And, we now have Google’s personal third-party high quality raters protesting for greater pay as not too long ago as February 2023, with claims of “poverty wages and no advantages.”
Add collectively all of this with the potential for human error, bias, scalability issues with the established order, the subjectivity of “relevance,” the shortage of true searcher context on the time of question and the lack to actually decide whether or not a question has a navigational intent.
And we now have not even touched upon the potential minefield of laws and privateness issues round implicit suggestions.
The right way to cope with lack of scale and “human points”?
Enter giant language fashions (LLMs), ChatGPT and rising use of machine-generated artificial knowledge.
Is the time proper to take a look at changing ‘the gang’?
A 2022 analysis piece from “Frontiers of Data Entry Experimentation for Analysis and Training” involving a number of revered info retrieval researchers explores the feasibility of changing the gang, illustrating the dialog is effectively underway.
Clarke et al. state:
“The current availability of LLMs has opened the likelihood to make use of them to robotically generate relevance assessments within the type of choice judgements. Whereas the thought of robotically generated judgements has been checked out earlier than, new-generation LLMs drive us to re-ask the query of whether or not human assessors are nonetheless essential.”
Nevertheless, when contemplating the present state of affairs, Clarke et al. increase particular issues round a doable degradation within the high quality of relevance labeling in trade for enormous scale potentials:
Issues about decreased high quality in trade for scale?
“It’s a concern that machine-annotated assessments may degrade the standard, whereas dramatically rising the variety of annotations obtainable.”
The researchers draw parallels between the earlier main shift within the info retrieval area away from skilled annotators some years earlier than to “the gang,” persevering with:
“However, an analogous change when it comes to knowledge assortment paradigm was noticed with the elevated use of crowd assessor…such annotation duties have been delegated to crowd employees, with a considerable lower when it comes to high quality of the annotation, compensated by an enormous improve in annotated knowledge.”
They surmise that the feasibility of “over time” a spectrum of balanced machine and human collaboration, or a hybrid method to relevance labeling for evaluations, could also be a approach ahead.
A variety of choices from 0% machine and 100% human proper throughout to 100% machine and 0% human is explored.
The researchers take into account choices whereby the human is initially of the workflow offering extra detailed question annotations to help the machine in relevance analysis, or on the finish of the method to test the annotations supplied by the machines.
On this paper, the researchers draw consideration to the unknown dangers that will emerge by way of the usage of LLMs in relevance annotation over human crowd utilization, however do concede in some unspecified time in the future, there’ll probably be an business transfer towards the substitute of human annotators in favor of LLMs:
“It’s but to be understood what the dangers related to such know-how are: it’s probably that within the subsequent few years, we are going to help in a considerable improve within the utilization of LLMs to interchange human annotators.”
Issues transfer quick on the planet of LLMs
However a lot progress can happen in a 12 months, and regardless of these issues, different researchers are already rolling with the thought of utilizing machines as relevance labelers.
Regardless of the issues raised within the Clarke et al. paper round decreased annotation high quality ought to a large-scale transfer towards machine utilization happen, in lower than a 12 months, there was a major growth that impacts manufacturing search.
Very not too long ago, Mark Sanderson, a well-respected and established info retrieval researcher, shared a slide from a presentation by Paul Thomas, one in every of 4 Bing analysis engineers presenting their work on the implementation of GPT-4 as relevance labelers slightly than people from the gang.
Researchers from Bing have made a breakthrough in utilizing LLMs to interchange “the gang” annotators (in complete or partially) within the 2023 paper, “Giant language fashions can precisely predict searcher preferences.”
The enormity of this current work by Bing (when it comes to the potential change for search analysis) was emphasised in a tweet by Sanderson. Sanderson described the discuss as “unbelievable,” noting, “Artificial labels have been a holy grail of retrieval analysis for many years.”
Whereas sharing the paper and subsequent case research, Thomas additionally shared Bing is now utilizing GPT-4 for its relevance judgments. So, not simply analysis, however (to an unknown extent) in manufacturing search too.
So what has Bing achieved?
The usage of GPT-4 at Bing for relevance labeling
The standard method of relevance analysis sometimes produces a different combination of gold and silver labels when “the gang” supplies judgments from express suggestions after studying “the rules” (Bing’s equal of Google’s High quality Raters Information).
As well as, stay checks within the wild using implicit suggestions sometimes generate gold labels (the fact of the true world “human within the loop”), however with a scarcity of scale and excessive relative prices.
Bing’s method utilized GPT-4 LLM machine-learned pseudo-relevance annotators created and skilled by way of immediate engineering. The aim of those cases is to emulate high quality raters to detect relevance primarily based on a rigorously chosen set of gold customary labels.
This was then rolled out to offer bulk “gold label” annotations extra broadly by way of machine studying, reportedly for a fraction of the relative price of conventional approaches.
The immediate included telling the system that it’s a search high quality rater whose goal is to evaluate whether or not paperwork in a set of outcomes are related to a question utilizing a label decreased to a binary related / not related judgment for consistency and to reduce complexity within the analysis work.
To combination evaluations extra broadly, Bing typically utilized as much as 5 pseudo-relevance labelers by way of machine studying per immediate.
The method and impacts for price, scale and purported accuracy are illustrated under and in contrast with different conventional express suggestions approaches, plus implicit on-line analysis.
Curiously, two co-authors are additionally co-authors in Bing’s analysis piece, “The Crowd is Made from Individuals,” and undoubtedly are effectively conscious of the challenges of utilizing the gang.

With these findings, Bing researchers declare:
“To measure settlement with actual searchers wants high-quality “gold” labels, however with these we discover that fashions produce higher labels than third-party employees, for a fraction of the price, and these labels allow us to practice notably higher rankers.”
Scale and low-cost mixed
These findings illustrate machine studying and huge language fashions have the potential to cut back or get rid of bottlenecks in knowledge labeling and, due to this fact, the analysis course of.
It is a sea-change pointing the way in which to an unlimited step ahead in how analysis earlier than algorithmic updates are undertaken for the reason that potential for scale at a fraction of the price of “the gang” is appreciable.
It is not simply Bing reporting on the success of machines over people in relevance labeling duties, and it’s not simply ChatGPT both. Loads of analysis into whether or not human assessors may be changed partially or wholly by machines is actually selecting up tempo in 2022 and 2023 in different analysis, too.
Others are reporting some success in using machines over people for relevance labeling, too
In a July 2023 paper, researchers on the College of Zurich discovered open supply giant language fashions (FLAN and HugginChat) outperform human crowd employees (together with skilled relevance annotators and persistently high-scoring crowd-sourced MTurk human relevance annotators).
Though this work was carried out on tweet evaluation slightly than search outcomes, their findings have been that different open-source giant language fashions weren’t solely higher than people however have been virtually nearly as good of their relevance labeling as ChatGPT (Alizadeh et al, 2023).
This opens the door to much more potential going ahead for large-scale relevance annotations with out the necessity for “the gang” in its present format.
However what may come subsequent, and what’s going to turn out to be of ‘the gang’ of human high quality raters?
Accountable AI significance
Warning is probably going overwhelmingly entrance of thoughts for search engines like google. There are different extremely necessary concerns.
Accountable AI, as but unknown threat with these approaches, baked-in bias detection, and its elimination, or a minimum of an consciousness and adjustment to bias, to call however just a few. LLMs are inclined to “hallucinate,” and “overfitting” might current issues as effectively, so monitoring may effectively take into account components corresponding to these with guardrails constructed as essential.
Explainable AI additionally requires fashions to offer an evidence as to why a label or different kind of output was deemed related, so that is one other space the place there’ll probably be additional growth. Researchers are additionally exploring methods to create bias consciousness in LLM relevance judgments.
Human relevance assessors are monitored repeatedly anyway, so continuous monitoring is already part of the analysis course of. Nevertheless, one can presume Bing, and others, would tread far more cautiously with this machine-led method over the “the gang” method. Cautious monitoring can even be required to keep away from drops in high quality in trade for scalability.
In outlining their method (illustrated within the picture above), Bing shared this course of:
- Choose by way of gold labels
- Generate labels in bulk
- Monitor with a number of strategies
“Monitor with a number of strategies” will surely match with a transparent be aware of warning.
Subsequent steps?
Bing, and others, will little doubt look to enhance upon these new technique of gathering annotations and relevance suggestions at scale. The door is unlocked to a brand new agility.
A low-cost, vastly scalable relevance judgment course of undoubtedly provides a powerful aggressive benefit when adjusting search outcomes to satisfy altering info wants.
Because the saying goes, the cat is out of the bag, and one might presume the analysis will proceed to warmth as much as a frenzy within the info retrieval area (together with different search engines like google) within the brief to medium time period.
A spectrum of human and machine assessors?
Of their 2023 paper “HMC: A Spectrum of Human–Machine-Collaborative Relevance Judgement Frameworks,” Clarke et al. alluded to a possible method that may effectively imply subsequent levels of a transfer towards substitute of the gang with machines taking a hybrid or spectrum kind.
Whereas a spectrum of human-machine collaboration may improve in favor of machine-learned strategies as confidence grows and after cautious monitoring, none of this implies “the gang” will depart fully. The group could turn out to be a lot smaller, although, over time.
It appears unlikely that search engines like google (or IR analysis at giant) would transfer utterly away from utilizing human relevance judges as a guardrail and a sobering sense-check and even to behave as judges of the relevance labels generated by machines. Human high quality raters additionally current a extra sturdy technique of combating “overfitting.”
Not all search areas are thought of equal when it comes to their potential impression on the lifetime of searchers. Clarke et al., 2023, stress the significance of a extra trusted human judgment in areas corresponding to journalism, and this could match effectively with our understanding as SEOs of Your Cash or Your Life (YMYL).
The group may effectively simply tackle different roles relying upon the weighting in a spectrum, probably shifting into extra of a supervisory position, or as an examination marker of machine-learned assessors, with exams supplied for giant language fashions requiring explanations as to how judgments have been made.
Clarke et al. ask: “What weighting between human and LLMs and AI-assisted annotations is right?”
What weighting of human to machine is carried out in any spectrum or hybrid method may depend upon how rapidly the tempo of analysis picks up. Whereas not fully comparable, if we have a look at the herd motion within the analysis area after the introduction of BERT and transformers, one can presume issues will transfer in a short time certainly.
Moreover, there’s additionally an enormous transfer towards artificial knowledge already, so this “path of journey” matches with that.
Based on Gartner:
- “Options corresponding to AI-specific knowledge administration, artificial knowledge and knowledge labeling applied sciences, goal to unravel many knowledge challenges, together with accessibility, quantity, privateness, safety, complexity and scope.”
- “By 2024, Gartner predicts 60% of knowledge for AI might be artificial to simulate actuality, future eventualities and de-risk AI, up from 1% in 2021.”
Will Google undertake these machine-led analysis processes?
Given the sea-change to decades-old practices within the analysis processes broadly utilized by search engines like google, it might appear unlikely Google wouldn’t a minimum of be trying into this very intently and even be striving in the direction of this already.
If the analysis course of has a bottleneck eliminated by way of the usage of giant language fashions, resulting in massively decreased knowledge sparsity for relevance labeling and algorithmic replace suggestions at decrease prices for a similar, and the potential for greater high quality ranges of analysis too, there’s a sure sense in “going there.”
Bing has a major business benefit with this breakthrough, and Google has to remain in and lead, the AI sport.
Removals of bottlenecks have the potential to massively improve scale, significantly in non-English languages and into extra markets the place labeling might need been tougher to acquire (for instance, the subject material skilled areas or the nuanced queries round extra technical subjects).
Whereas we all know that Google’s Search Generative Expertise Beta, regardless of increasing to 120 international locations, remains to be thought of an experiment to learn the way individuals may work together with or discover helpful, generative AI search experiences, they’ve already stepped over the “AI line.”

Nevertheless, Google remains to be extremely cautious about utilizing AI in manufacturing search.
Who can blame them for all of the antitrust and authorized instances, plus the prospect of reputational injury and rising laws associated to person privateness and knowledge safety laws?
James Manyika, Google’s senior vp of know-how and society, talking at Fortune’s Brainstorm AI convention in December 2022, defined:
“These applied sciences include a unprecedented vary of dangers and challenges.”
Nevertheless, Google isn’t shy about enterprise analysis into the usage of giant language fashions. Heck, BERT got here from Google within the first place.
Actually, Google is exploring the potential use of artificial question technology for relevance prediction, too. Illustrated on this current 2023 paper by Google researchers and introduced on the SIGIR info retrieval convention.

Since artificial knowledge in AI/ML reduces different dangers that may relate to privateness, safety, and the usage of person knowledge, merely producing knowledge out of skinny air for relevance prediction evaluations may very well be much less dangerous than among the present practices.
Add to the opposite components that might construct a case for Google leaping on board with these new machine-driven analysis processes (to any extent, even when the spectrum is usually human to start with):
- The analysis on this area is heating up.
- Bing is working with some business implementation of machine over individuals labeling.
- SGE wants a great deal of labels.
- There are scale challenges with the established order.
- The rising highlight on the usage of low-paid employees within the data-labeling business general.
- Revered info retrieval researchers are asking is now the time to revisit the usage of machines over people in labeling?
Brazenly discussing analysis as a part of the replace course of
Google additionally appears to be speaking far more brazenly of late about “analysis” too, and the way experiments and updates are undertaken following “rigorous testing.” There does appear to be a shift towards opening up the dialog with the broader group.
Right here’s Danny Sullivan simply final week giving an replace on updates and “rigorous testing.”

And once more, explaining why Google does updates.

Search off The Document not too long ago mentioned “Steve,” an imaginary search engine, and the way updates to Steve is likely to be carried out primarily based on the judgments of human evaluators, with potential for bias, amongst different factors mentioned. There was an excellent quantity of dialogue round how modifications to Steve’s options have been examined and so forth.
This all appears to point a shift round analysis until I’m merely imagining this.
In any occasion, there are already parts of machine studying within the relevance analysis course of, albeit implicit suggestions. Certainly, Google not too long ago up to date its documentation on “how search works” round detecting related content material by way of aggregated and anonymized person interactions.
“We rework that knowledge into indicators that assist our machine-learned methods higher estimate relevance.”
So maybe following Bing’s lead isn’t that far a leap to take in any case?
What if Google takes this method?
What may we anticipate to see if Google embraces a extra scalable method to the analysis course of (enormous entry to extra labels, probably with greater high quality, at decrease price)?
Scale, extra scale, agility, and updates
Scale within the analysis course of and speedy iteration of relevance suggestions and evaluations pave the way in which for a a lot higher frequency of updates, and into many languages and markets.
An evolving, iterative, alignment with true relevance, and algorithmic updates to satisfy this, could possibly be forward of us, with much less broad sweeping impacts. A extra agile method general.
Bing takes a way more agile method of their analysis course of already, and the breakthrough with LLM as relevance labeler makes them much more so.
Fabrice Canel of Bing, in a current interview, reminded us of the search engine’s consistently evolving analysis method the place the push out of modifications isn’t as broad sweeping and disruptive as Google’s broad core replace or “large” updates. Apparently, at Bing, engineers can ideate, acquire suggestions rapidly, and typically roll out modifications in as little as a day or so.
All search engines like google could have compliance and strict evaluation processes, which can’t be conducive to agility and can little doubt construct as much as a type of course of debt over time as organizations age and develop. Nevertheless, if the relevance analysis course of may be shortened dramatically whereas largely sustaining high quality, this takes away a minimum of one large blocker to algorithmic change administration.
We now have already seen an enormous improve within the variety of updates this 12 months, with three broad core updates (relevance re-evaluations at scale) between August and November and plenty of different modifications regarding spam, useful content material, and critiques in between.
Coincidentally (or most likely not), we’re informed “to buckle up” as a result of main modifications are coming to go looking. Modifications designed to enhance relevance and person satisfaction. All of the issues the gang historically supplies related suggestions on.

So, buckle up. It’s going to be an fascinating journey.

If Google takes this route (utilizing machine labeling in favor of the much less agile “crowd” method), anticipate much more updates general, and certain, many of those updates might be unannounced, too.
We might probably see an elevated broad core replace cadence with decreased impacts as agile rolling suggestions helps to repeatedly tune “relevance” and “high quality” in a sooner cycle of Studying to Rank, adjustment, analysis and rollout.
Opinions expressed on this article are these of the visitor writer and never essentially Search Engine Land. Employees authors are listed right here.